Problem statement
Design a large chat system for companies, similar to Slack. Notice to limit the scope and choose the most unique and critical components to discuss. Should avoid mention not critical part or the parts that you are not familiar with. Choose a coherent structure to describe. In each section, whenever you stuck, try to move forward without wasting a lot of time.
Requirements
Functional requirements
- create a channel (multiple or single recipient)
- send and receive messages in a channel
- receive message for offline user
- send multi-media files
Below the line
- private channel
Non-functional requirements
- low latency (<500ms)
- high throughput (1billion) scalability
- guarantee receive once delivery
- availability (99.9% or 99.99%)
- fault tolerance (?????)
Below the line
- security model (encryption, store the message in the server)
Core entities
- message
- channel (chat)
- User(participants, sender, recipient)
API overview
- create_channel/[channel_id]
- add_participant/[participant_id]
- send_message/[message_id]
- receive_message/[channel_id]
- creat_file/ # create a blob data
- send_file/ # send the created blob data to the channel
- updat_participant/ # handle join or delete of a participant
Q: what’s the order of importance of the API? or what the structure we should keep in mind when list the API, because it could be a lot of functionalities, if you list too much, you’ll have no time to talk about in later design. If you miss the important one, you’ll look bad and interviewer might thought you don’t know. so, comeup a framework that can guide you to make the API and the design consistent.
Basic design
MVP
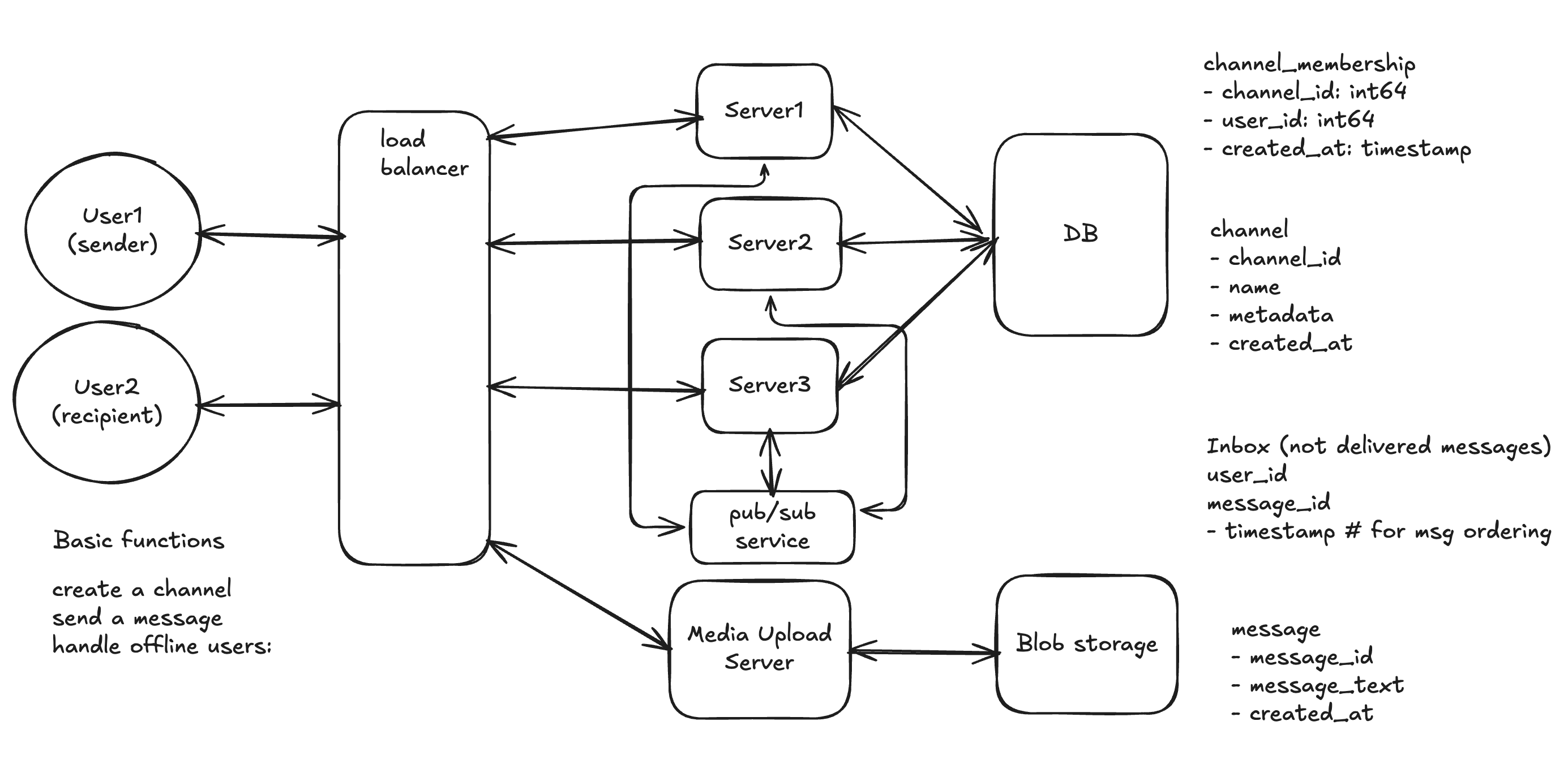
During interview, it’s better to split the service based on the functionality. For example, we can have separate server for chat server, channel server, message server, inbox server, etc. This is good for discussion about scalability and fault tolerance in the next step. To scale the system, you just need to duplicate these server for each service. When you need to scale the system, you can use the server box to represent the server cluster for each service. So you don’t have to draw too many boxes in the diagram.
Work flow
Send message (single server)
- User send message to load balancer, which routes the request a chat server.
- Chat server process the message and store the message to DB. The chat server then need to get the recipient list from channel server, chat server should have a map of participant id to participant connection. Here we can use WebSocket or gRPC stream to maintain the connection.
- Chat server push the message to each recipient user through the maintained connection.
Send message (multiple server)
To scale the service to billions of users, we need to have multiple chat server to handle the message sending and receiving. The challenge here is that the chat server which process the message may not maintain the connection for each recipient user. So how to deliver the message to each recipient user?
- User send message to load balancer, which routes the request a chat server.
- Chat server process the message and store the message to DB. The chat server then need find the server which maintain the connection for each recipient user. Here we can use consistent hashing to find the server for each recipient user.
- Chat server push the message to each recipient user through the maintained connection.
Better approach is to use a message queue to decouple the chat server and the message delivery. The chat server just need to push the message to the message queue, and each server which maintains the connection to recipients can subscribe to the message queue to forward the message to the users.
Offline message
- User send message to load balancer, which routes the request a chat server.
- Chat server process the message and store the message to DB. The chat server then need find the server which maintain the connection for each recipient user. Here we can use consistent hashing to find the server for each recipient user.
- If the recipient user is offline, the chat server store the message to inbox server for later delivery.
- When the user comes online, the chat server fetch the message from inbox server and push the message to the user.
Data model
channel_membership
- channel_id: int64
- participant_id: int64
- created_at: timestamp
channel
- channel_id
- name
- metadata
- created_at
Inbox (only for not delivered messages)
- user_id
- message_id
- timestamp # for msg ordering
message
- message_id
- message_text
- created_at
Deep dive topics
- handle multiple clients
- ensure message order (DB system design)
- handle simultaneous messages.
- realtime status feature
- sync read status across devices (consistent model)
- multi-tenancy for multiple companies?
- what if (websocket server, gateway, DB instance) die?
- reconnect in poor network (or switch network (e.g. cellular to wifi))
- other failure topics:
- How clients reconnect (using exponential backoff).
- How to get missed messages after a reconnect.
- Database replication (keeping copies of data).
- “Thundering herd” problem (everyone reconnecting at once).
- Keeping WebSocket servers “stateless” so they are easy to add or remove.
- reconnect without thunder herd(exponential back-off)
- How does this exactly work in a real situation?
- stateless websocket connection (distributed session storage, can resume session on connection failure) gateway should tateless, only keep the connection_id to the user_id/device_id. Store session info in the distributed cache (Redis). If gateway dies, user reconnect to another box, can resume the session by reading the session info from cache, then e-subscribing/catch up the undelivered messages.
- presence/connection directory (backed by distributed key-value store such as Redis or similar) that store
user_id → {gateway_id, connections, last_heartbeat} - fanout messages
- consistent hashing, deterministic mapping from
user_id → gateway_shard. requires rebalancing on auto scale or failure. - pub/sub message queue (best solution)
- consistent hashing, deterministic mapping from
- inbox/delivery tracking
- don’t store the undelivered message, use a cursor instead.
user_channel_cursor(workspace_id, user_id, channel_id, last_delivered_seq, last_read_seq)- on reconnect, client ask: give me messages from seq > last_delivered_seq
- don’t store the undelivered message, use a cursor instead.
- messaging ID and ordering (per channel order is good enough)
- use UUID, ordering comes from message_seq, which is a per channel monotonic
- generate message_seq from DB atomic counter per channel (can be hot for huge channel)
- shard large channels: partition by “time bucket” an use (bucket, seq) ordering.
- use SnowflakeID
(timestamp (41 bits) + machineID (10 bits) + sequence (12 bits))
- use UUID, ordering comes from message_seq, which is a per channel monotonic
- guarantee semantics (at-least-once delivery)
- idempotency key
- sync read status across devices
- store last_read_seq in
user_channel_cursor - device mark as read, publish `ReadUpdate(user_id, channel_id, last_read_seq)
- fanout to other device of same user to sync.
- eventual consistency is find, it’s tolerable
- store last_read_seq in
- presence/realtime status update
- gateways heartbeat to the presence service
- best-effort
- on connect, send a notification to the presence service, then send heartbeat.
- TLL-based status, if no heartbeat for x ms, mark offline
- multi-tenancy
- workspace_id is included in every db primary key
- shared cluster + workspace_id partitioning (logical)
- physical host isolation (encryption keys, stricter isolation)
- auth process need redirect to the right workspace
- encryption in transit always, encryption at rest with per-tenant keys for enterprise.
- What if the pub/sub queue is down?
- use outbox pattern
- write message and outbox event in same DB transaction
- background publisher drains outbox to queue
- use outbox pattern